I was discussing how AI text generation, such as ChatGPT, might end up getting used in computer games. So far, designers are fairly reluctant to adopt the technology. One of the key problems is that you just can’t control the output enough. Language models will break character or respond in inappropriate and toxic ways. Finding a good solution to this is a huge research field, and not likely to get cracked soon.
For the foreseeable future, AI in games is much more likely to be used offline – assets and dialog generation generated up front, so it can be vetted before being integrated into the game.
But it got me thinking, can we vet the AI’s output in advance, but still get the benefits of intelligent decision making at runtime? It turns out, we can! I doubt it’ll be useful in every circumstance, but I can certainly see uses for it, like chatbots, games.
The code and demonstration for this article is available here.
The Just Man

In Gene Wolfe’s masterpiece The Book of the New Sun, he introduces a nation of people called the Ascians. The Ascians live in a totalitarian state so absolute that they have been indoctrinated to only speak in complete sentences quoted directly from propaganda texts. It’s a sort of culmination of 1984’s newspeak.
Nonetheless, the Ascians are intelligent, thinking people. The story-within-a-story “The Just Man” is narrated by an Ascian, and shows how meaning can be conveyed even when so ridiculously constricted. You can read the story here.
We’re going to apply the same technique on a Large Language Model text generator. We’ll restrict the output to only a set of approved sentences, but use all the smarts of the model in deciding which sentence to use. This will go a long way towards ensuring the generation stays on track. Though it’s hardly a bulletproof solution, I think it could be useful in some contexts.
Guided Text Generation
The technique we’re going to use is a simplified version of “guided text generation“, also known as constrained beam search. It’s explained very well here and here, but I’ll give a high-level overview which doesn’t assume much knowledge of ML.
The way large language models like GPT work is that they are trained to do next token prediction. I.e. to answer the question: “given the first half of a sequence of text, what is likely to come next?”. There obviously isn’t a single answer, so they give a distribution of likely answers. They only predict a single token at a time, a token being a short snippet of text at most one word long.

If you can answer that question reliably, you can make a text generator for any length of text. You start with some input text (the prompt) and predict the next token. Pick the most likely token, and add it to the input text. Then you can predict the token after that, and repeat until you’ve built up a text and got to a predicted termination token.
This isn’t really that different from Markov Chains Text generation, a fun and easy procedural generation technique. We just have a more sophisticated prediction.
Picking the most likely token is called a greedy search. It doesn’t always give good results. By always picking the most plausible token, we miss out on many plausible sentences that happen to have an unlikely token near the start. Instead, a variety of search techniques have been introduced that explore the possibilities of a sentence, from left to right. The most common is beam search, which simultaneously explores several branches of the search tree.
A number of other options such as temperature and top-k filtering are also used to direct the search.
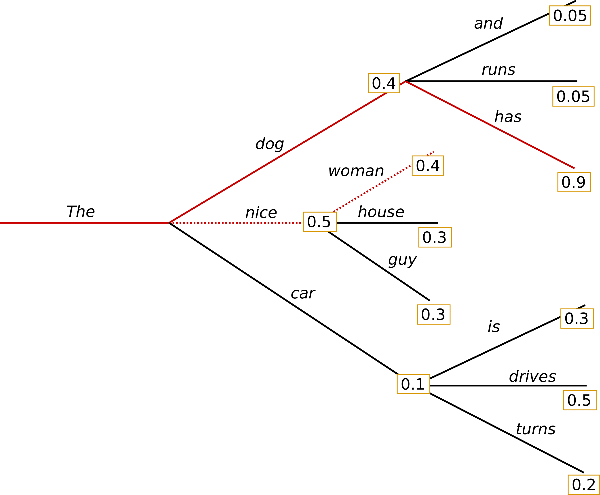
Fixed Phrases
So text generation involves exploring a tree of possible sentences. If we want to restrict the generation to a set of phrases, one way would be to restrict the tree that is explored to just include the phrases we want.
OpenAI’s API doesn’t support that, so I can’t try this idea out on the latest models. But fortunately, HuggingFace has a feature called prefix_allowed_tokens_fn that lets us do exactly that. This setting lets us filter the list of potential tokens at any point in the tree search. All we need do is check what has been generated so far, find the phrases that start with that prefix and filter the next tokens to those that continue the phrases.
The results are promising. I tried this with the gpt2, an older language model. Without restrictions, it rarely behaves how you want, as it has not been trained to answer questions (unlike ChatGPT). I list the top 5 possible responses, in order.
Q: How many quarts in a gallon?
Output:
score -0.67: '\n\nIf you want to know how many qu'
score -0.68: '\n\nHow many gallons of water do you need'
score -0.71: '\n\nIt depends on the size of the qu'
score -0.72: '\n\nIt depends on how much water you use'
score -0.73: '\n\nIt depends on the size of the container'Then I added a restricted set of phrases, one of: "My name is Bob.", "My name is Alice.", "Yes", "No", "13".
Now that those are the only options, it’s much more likely to answer the question as it only has one sensible option. Notice how ’13’ has a much higher score than the alternatives. It doesn’t matter that it’s factually false, it’s still the most plausible answer.
Q: How many quarts in a gallon?
Output:
score -2.06: '13'
score -2.21: 'No'
score -2.24: 'Yes'
score -2.55: 'My name is Bob.'
score -2.68: 'My name is Alice.'It answers other questions sensibly too, though this technique does nothing to improve accuracy.
Q: Is Everest a mountain?
Output:
score -2.73: 'No'
score -2.79: 'Yes'
score -3.09: 'My name is Bob.'
score -3.13: '13'
score -3.21: 'My name is Alice.'
Q: What is your name?
Output:
score -2.49: 'My name is Bob.'
score -2.55: 'My name is Alice.'
score -3.05: 'Yes'
score -3.12: '13'
score -3.15: 'No'I expect with a proper bank of phrases, this model might communicate tolerably well. We could even attach code to those phrases, so for example, when the chatbot selects the phrase “Your current balance is:”, or “I surrender” we could follow it with balance information, in-game actions, etc.
Extensions
Really, if you have a fixed set of phrases, there’s not much point doing a tree search at all, unless it’s a truly huge bank of them. You can just evaluate each phrase independently, or treat it as a categorization problem.
But you don’t need to use a fixed set. Any tree filter will work. So you could design your own grammar with a tool like Tracery, and then let the AI pick phrases for it.
Or you can enforce that the output of the generator follows a fixed structure, if you want to parse out specific details reliably. In the notebook, I experiment with enforcing JSON like behaviour. GPT is smart enough to understand JSON, but not smart enough to follow a fixed schema without help.
Q: The names of the world's largest cities as a json array of strings:
Output:
score -0.73: ' [ "London", "New York", "Paris", "Tokyo", "Moscow", "San Francisco", "Los Angeles", "Miami", "'
score -0.74: ' [ "London", "New York", "Paris", "Tokyo", "Los Angeles", "San Francisco", "Toronto", "London" ]'
...
Conclusion
Has anyone else explored this sort of thing? I don’t know, I’m pretty new to AI.
Restricting the output of an AI obviously handicaps its capabilities, so I can’t imagine there will be many uses. But I think it would still be possible to improve on non-ML chatbots this way, without quite such a dangerous surface area.
Of course, the AI output can still go disastrously wrong. Innocuous phrases can take on new meanings when placed in the right context. And for many purposes you’ll need generic phrases like “Yes” / “No” which barely constrain the AI at all.
This is super neat. I suspect there are tons of applications for stuff like One Page Dungeon and other similar content generators.
I think there’s value in framing this as less about constraining the LLM and more about guiding Tracery (or equivalent)? It might mean that the Tracery grammar can be a lot more open ended, since the LLM will (hopefully) filter the possible nonsense outputs away better.
Very thought provoking post, as usual. Thanks for the example code too, super useful.
If the grammar is comprehensive enough this would be neat for generating interesting stories or dialog out of only true (or deliberately deceptive) statements. This is a good way to prevent llm hallucinations.