Previously we considered the Arc Consistency 3 and Arc Consistency 4 algorithms, which are an essential component of many constraint solvers. I’ve been using AC-4 myself for some time, and I naturally got curious as to what other improvements can be made.
Diving it, I discovered there is a huge amount of papers with new innovations are refinements on these two fundamental techniques. I’m going to attempt to summarize them there, and maybe later experiment with them in my own software, but I’m afraid this article is going to be pretty niche.
Research focus has shifted somewhat – most algorithms are concerned with generalized arc consistency, i.e. dealing with constraints that cover more than two variables.
You are strongly adviced to read my article on AC-3/4 before starting this one, as I use the same terminology and concepts.
AC-5
The first thing to discuss is AC-5. AC-5 is not so much an algorithm as it is a generic framework for other algorithms. Here’s the main loop of AC-5.
AC-5 Loop Listing
- Start with an empty queue of (constraint, variable, value) tuples
- For each constraint:
- Find all the inconsistent (variable, value) pairs
- For each inconsistent (variable, value) pair:
- Add it to the queue with the constraint
- Remove the value from the domain of the variable
- Initialize any datastructures
- While the queue is non-empty:
- Remove a (constraint, variable, value) tuple from the queue
- Find newly inconsistent (variable, value) pairs, given the removed tuple
- For each inconsistent (variable, value) pair:
- Remove the value from the domain of the variable
- For each constraint involving the variable excluding the original constraint:
- Add a tuple to the queue.
It’s actually a very similar loop to AC-4. In both cases, we have a queue, which records which values have been removed from which domains. And we have 3 abstract operations, that need to be specified later:
Initialize: Initialize datastructureArcCons: Find all inconsistent pairs for one constraintLocalArcCons: Find newly inconsistent pairs for one constraint, given a removed value (or set or values)
AC-5 doesn’t specify what these operations are. We can swap them out all sorts of different choices, and get a whole variety of different algorithms.
For example, to get AC-3 behaviour, we’d use:
Initialize: Do nothingArcCons: Loop over all values, and search each for support. Report those with no support.LocalArcCons: Same as ArcCons
Or get AC-4 behaviour, we’d use:
Initialize: Set up counter arrays with a count of support for each value.ArcCons: Report all the counters that are zero.LocalArcCons: Decrement counters related to the removed value, and report counters that have reached zero.
Note that AC-3 doesn’t use the local information about what values have changed at all, as LocalArcCons and ArcCons do the same thing. Algorithms like this are called “coarse”, while ones that need that information are called fine. Coarse grained algorithms are not necessarily slower – they need less information tracked to operate, and are typically more efficient when the conditions of the constraint change a lot from one invocation to the next.
The vast majority of algorithms I looked at fit into the AC-5 loop and can be classified as either coarse or fine.
Backtracking
The point of arc-consistency is to use this algorithm as part of a constraint solver. That means we’re not going to just run it once, but instead repeatedly as we make solver progress. And worse, most solvers have a notion of backtracking, where they give up on an area of search, and revert progress to an earlier state. That means any algorithm that stores any information must use a datastructure that is capable of efficient backtracking without using too much time or memory, which are called reversible data structures.
There’s a couple of different approaches to reversible data structures.
- Keep a full copy of the data at each backtrack point. Only really works for small amounts of data.
- Use a persistent data structure, where the data is stored as a series of patches. This doesn’t seem to be popular.
- Store data in such a way that it is still valid after backtrack, unchanged.
- Record sufficient information that we can undo any changes that have occured. This is called trailing.
The majority of algorithms use trailing, which can be simply done by inspecting any given stored data before changing it, and writing a lot of all changes. There are other trailing techniques though, such as Sparse Set.
Sparse Set
Many of the algorithms use a data structure called a Sparse Set. Sparse Set stores a set of integers in the range 1-n, and elements can be removed from a set in a way that is efficient to back track. (you cannot add elements though, the set only ever gets smaller). It roughly works as follows:
Start with an array containing the values 1 to n, called Dyn. Populate another array Map, which gives the index of each value in Dyn (i.e. Dyn[Map[i]] == i). Finally store a Size, also initially n.
Map is just used to ensure O(1) set membership tests. A value x is currently in the set if Map[x] <= Size.
Each time we remove a value from the set, we find the location in Dyn of the value (using Map), and swap it with the value at Dyn[Size]. Map is then updated, and Size reduced by one. So as values are removed, they are swept to the end of Dyn, in order of removal, and the Size parameter indicates they are unused.
To backtrack, it’s just necessary to restore Size to the old value. Map and Dyn do not need to be changed, as the order of elements in Dyn is unimportant, only whether they are positioned before/after Size.
Classifying Algorithms
So what about more sophisticated data structures? Well, there’s too much to explain here, but I will attempt to summarize. The main bottleneck becomes the size of the table describing, which can be huge. There’s three main approaches to tackling it:
Indexing attempts to analyse the table in advance, and build structures for quickly querying it. For example, in many cases it’s useful to compile lists of tuples from the table that have a particular value at a given variable.
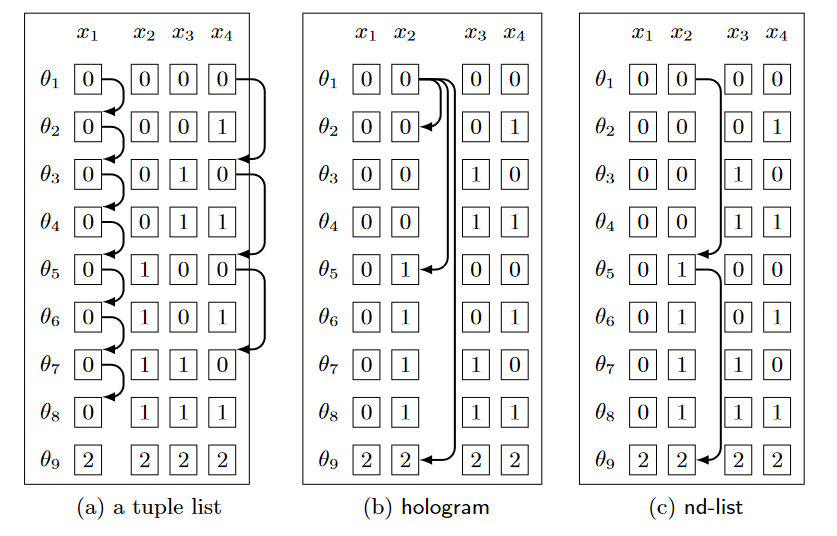
Compression attempts store the table in a more efficient format, that takes advantage of redundancy while searching it. My article on Compressed Sparse Fibers is an example of compression, though that particular compression isn’t that useful in this context.
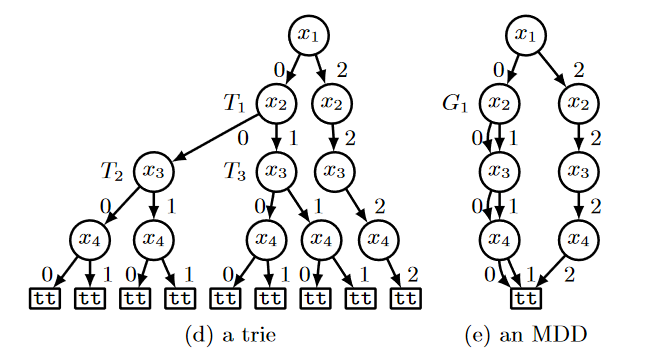
Dynamic tables attempts to remove tuples from the table as they become invalid. That stops you having to search them over and over again. But it’s difficult to trail or index efficiently.
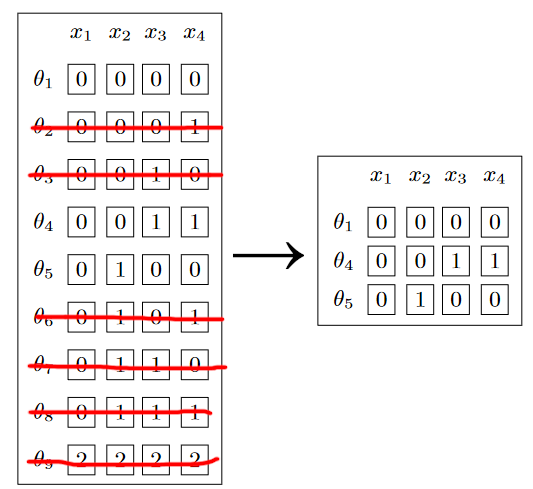
List of Table Constraint Algorithms
Finally, I think we’ve ready to cover some specific algorithms. They are unfortunately too many and too complex to cover in any detail, and I cannot say I understand them greatly, so I’ve simply made a table of abridged notes.
You might be better off reading a recent literature review, which goes into considerable more detail.
In my notes below, per-value usually means per-constraint-variable-value, and I write tuple when I usually mean allowed tuple. Static indicates something doesn’t change after initialization, while unmaintained means it does change, but it doesn’t need trailing. An inverse index for an array of values a[x] = b, you store an array of sets {x | a[x] = b} for each b.
| Algo | Paper | Type | Description |
|---|---|---|---|
| AC3 | Mackworth 1977 | Coarse | Simply loop over all values and tuples. |
| GAC2001 | Bessiere 2005 | Coarse | Store the smallest valid tuple per value |
| GAC3rm | Lecoutre 2007 | Coarse | Store a arbitrary unmaintained valid tuple per value, but re-use it for every variable of the constraint. |
| AC4 | Mohr 1986 | Fine | Store a count of valid tuples per value, and a static list of valid tuples per value. |
| AC5 | van Hentenryck 1992 | Fine | Paper describes the loop/datastructure separation I use above. Also how to implement certain simple constraints efficiently. |
| GAC4 | Mohr 1988 | Fine, Generalized | Store a linked list of valid tuples per-value. |
| AC6 | Bessiere 1994 | Fine | Store the smallest valid tuple per value, inverse indexed by the other value. |
| STR2 | Lecoutre 2008 | Coarse, Generalized, Dynamic | STR introduces the Sparse Set concept and stores a list of valid tuples with it. STR2 introduces further runtime optimizations, such as tracking which variables have changed. |
| STR3 | Lecoutre 2015 | Fine, Generalized, Dynamic, Index | Stores a static index of tuples per value, a sparse set of invalid tuples, and a “separator” per value that tracks the greatest valid tuple, and an unmaintained inverse index of the separator. So essentially STR2 + AC6 + “watched literals”? |
| MDDc | Cheng 2010 | Coarse, Generalized, Compressed | Stores a MDD – a trie with merged subtrees and walks it incrementally with sparse sets. |
And here are references (generally the original paper) for each algo.
| Algo | Paper | |
|---|---|---|
| AC3 | A.K. Mackworth. Consistency in networks of relations. Artificial Intelligence, 8:99-118, 1977 | |
| GAC2001 | C. Bessiere, J.-C. Régin, R. Yap, and Y. Zhang. An optimal coarse-grained arc consistency algorithm. Artificial Intelligence, 165(2):16a5–185, 2005 | |
| GAC3rm | C. Lecoutre and F. Hemery. A study of residual supports in arc consistency. In Proceedings of IJCAI’07, pages 125–130, 2007. | |
| AC4 | R. Mohr and T.C. Henderson, Arc and path consistency revisited, Artif. lntell. 28 (1986) 225 -233 | |
| AC5 | van Hentenryck P, Deville Y, Teng CM (1992) A generic arc-consistency algorithm and its specializations. Artificial Intelligence 57(2-3):291–321 | |
| GAC4 | Roger Mohr, Gérald Masini: Good Old Discrete Relaxation. ECAI 1988: 651-656 | |
| AC6 | C. Bessiere 1994. Arc-consistency and arc-consistency again, Art. Int.65 (1994) 179–190 | |
| STR | Ullmann, J. R. (2007). Partition search for non-binary constraint satisfaction. Information Sci- ence, 177, 3639–3678. | |
| STR2 | Lecoutre C. (2008) Optimization of Simple Tabular Reduction for Table Constraints. In: Stuckey P.J. (eds) Principles and Practice of Constraint Programming. CP 2008 | |
| STR3 | Christophe Lecoutre, Chavalit Likitvivatanavong, Roland H.C. Yap, STR3: A path-optimal filtering algorithm for table constraints, Artificial Intelligence, Volume 220, 2015, Pages 1-27 | |
| MDDc | Kenil Cheng and Roland Yap (2010). An MDD-based Generalized Arc Consistency Algorithm for Positive and Negative Table Constraints and Some Global Constraints | |
| Summary | P. Van Hentenryck J.-B. Mairy and Y. Deville. Optimal and efficient filtering algorithms for table constraints. Constraints, 19(1):77–120, 2014 | |
| Summary | Yap, R.H.C., Xia, W., Wang, R. Generalized arc consistency algorithms for table constraints: A summary of algorithmic ideas. AAAI 2020 |
Summary
I’m not sure if there is a clear winner for techniques yet. It varies a lot according to the nature of the problem you are trying to solve. It doesn’t help that the field is extremely opaque – I’ve found no good writeups for anything, terminology varies from paper to paper, and even open source solvers rarely bother to explain which techniques they use internally. Pretty strange for a field that is decades old and has significant commercial implementations.
I realize now my own constraint library, DeBroglie bakes in many assumptions. Some of those are poor descisions in retrospect. I think STR3 looks the most promising to add, as I already support fine-grained notification, and it’s surprisingly simple for such an advanced technique.