Last article, we were comparing WaveFunctionCollapse (WFC), and Model Synthesis (MS). These are both similar procedural generation techniques that work along similar lines. Specifically, they generate a grid of tiles (or pixels), using a set of hard constraints, and some generalized solver technique to find a solution, a set of tiles that satisfies all the constraints provided. Let’s call this overall class of thing constraint-based tile generators.
The techniques have been pretty popular in recent years, and part of that is because it’s actually a very easy concept to experiment with and extend. Many of the more practical examples in the wild include their own extensions, as basic WFC tends to produce levels that look a bit repetitive and structureless.
Today I thought I’d do a review of all the different ways that you can customize this generation technique, showing how WFC and MS are subsets of a greater class. The whole family of such algorithms is much larger and I think there’s a lot of potential still to explore.
I’ll break down variations into a number of different aspects that can mostly independently be toyed with.
Table of Contents
Model
The defining aspect of constraint-based tile generation is the constraints. These are the rules specifying how tiles may and may not link together. Typically, the constraints are local, meaning each constraint only involves nearby tiles, and they are regular, meaning the same constraints are applied to every cell of the grid.
This set of constraints is sometimes called the “model”.
There’s only two models in popular use, Adjacency and Overlapping.
Adjacency
This model sets requirements about pairs of tiles that are directly adjacent to each other. Thus, there’s one constraint per edge in the grid. Adjacency models are sometimes called Wang tiles.


Claudio Rocchini CC BY-SA 3.0
Overlapping
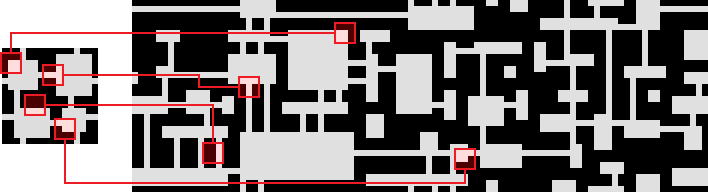
This model looks at small rectangular patches of tiles, and requires that the entire rectangle fit into one of a finite list of patterns. This model was introduced by Maxim Gumin as part of WaveFunctionCollapse, inspired by similar approaches in the texture synthesis world.
It’s more costly to evaluate than adjacencies, but it’s also capable of producing more interesting patterns and results.
Model Inference
The model is just a collection of constraints, but that doesn’t really answer the question of where those constraints are loaded from. Specifying constraints manually becomes incredibly tedious for larger tilesets, so we typically want to take information in a more compact and intuitive format, and then infer what constraints to use from that.
Sample-Based
The most popular approach is to supply the input in the form of already filled-in grid of tiles.
This is an very straightforward approach – the user simply draws a level or design they are interested in, and says “More Like This Please!”
The inference then looks at all the adjacencies or patterns in the sample, optionally rotates them, and then creates constraints that require the generated output has the same adjacencies / patterns.
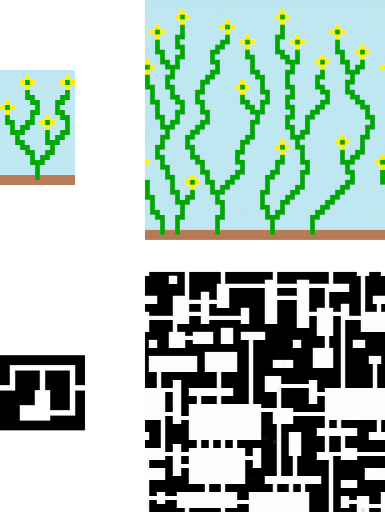
Example from the original WFC repo.
As far as I’m aware, this is the only practical way to specify constraints for overlapping models.
One drawback of sample-based approaches is that it’s often too precise – the model with learn details of the input that are incidental, and not intended by the user. The more tiles you have, the more common this is, as it’s near impossible to provide a sample that demonstrates every combinatorial use of all the tiles.
Labels
For adjacency constraints, the other obvious way to handle things is to label each side of the tile with a different value, and then specify that two tiles can be adjacent only if those labels exactly match (or some more advanced criteria about the labels).
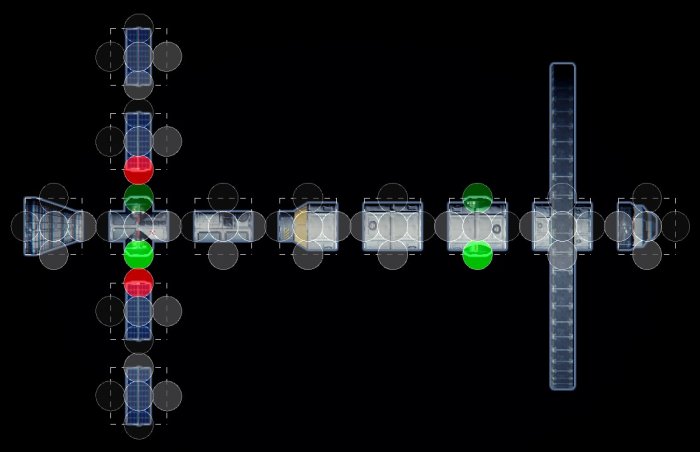
Labels avoid the combinatorial difficulties of samples, as you can annotate every tile separately and the inference puts it all together. But they’re harder to set up, as it requires visualizing how tiles connect and what consequences that has to the overall generation.
Not all label schemes use a single label per side. My software, Tessera, for example, uses nine labels per side. That gives the user slightly more options in terms of configuration, handles rotation better and allows small mnemonic patterns.
Content-Based
If you’ve ever tried manually labelling tiles, you quickly discover that usually the choice of label is pretty obvious from a single glance at the tile. After all, the point of labels is to ensure that tiles connect up smoothly, where smoothly means there’s no visual discontinuity between them.
So rather than define labels ourselves, we can just insist that tiles connect with no discontinuity.
If the tiles are images, that means inspecting the pixels on their border, as is done in Generate Worlds. If they are meshes, then you can just look at the vertices and edges of the mesh along the side of the tile, as shown in marian42’s city generator or the collected works of Oskar Stålberg.
Solver
The tiles and constraints of the model merely specify the requirements about what the output must look like. The heart of any constraint based technique is the solver, an algorithm for exploring the space of possible outputs for one that satisfies all the constraints specified. I go a bit more into how solvers work in Wave Function Collapse Explained.
Depending on the constraints, solving can be easy, or fiendishly difficult. There is a wide range of very advanced solvers available for difficult problems. For example, Tile Composer lets you use the Z3 solver. And I’ve seen some interesting results using Clingo.
Arc Consistency
However, these professional solvers are often quite cumbersome to use in practical settings, and don’t allow too much by way of customization. Instead, both WFC and Model Synthesis use a simpler approach, called Arc Consistency, which I have explained in detail before.
There’s two common variants, Arc Consistency 3 and Arc Consistency 4. Both are easy to implement and pretty quick, and while they can sometimes get stuck, it is still an effective choice for generation settings, where the problems are usually “easy”.
Another advantage of Arc Consistency is customizability. You can choise the cell heuristic, tile heuristic and constradiction handling as described below.
Cell Heuristic
The cell heuristic is how the solver chooses which cell to examine next. Recall that most solvers work by picking a cell, making a descion about what tile goes in it, propagating the consequences of that descision, then repeating.
The choice of cell is not usually an important descicion, as all cells will eventually be filled in, but I have noticed it can have interesting effects on quality and success rate of the output.
The two most common choices are linear scan, which runs over the cells in a fixed order (introduced by Model Synthesis), and min-entropy, which picks the cell with the smallest choice of tiles remaining (introduced by Wave Function Collapse).
Tile Heuristic
After picking the cell, you must pick which tiles goes into that cell. Most commonly is weighted random choice, but an interesting variant is seen in Townscaper, which always picks the highest “priority” tile available. This gives a much more deterministic output, which suits the game as users can reliably cause interesting, obscure, tiles to appear by creating the right pattern for them.
More custom tile heuristics can be chosen to fit the specifics of the level you are trying to produce, with a wide variety of effects. Unlike the constraints, which are always satisfied, heuristic good place to fiddle with features that are nice to have, but not strictly required (soft constraints). For example, controlling the frequency of tiles in different areas, or ensuring the level is easy to navigate.
Contradictions
It’s a fact of any constraint based approach that you will face contradictions – situations where the partially generated level is impossible to extend any further without breaking a constraint.
I go into this in considerable detail in my article on Model Synthesis, but your choices are essentially:
- Restarting – when a contradiction occurs, restart from scratch. Hopefully they are rare enough you’ll succeed in a few attempts
- Backtracking – take one step back to a known good state, and try some other choice of tile. Can still get stuck if the problem space is too large
- Modifying in blocks – generate the level one chunk at a time, and do restarts per chunk.
- Conflict Driven Clause Learning – what the “pro” constraint solvers usually do. This is generally too difficult to difficult to implement in most circumstances. There’s a bunch of other techniques too that I can’t go into here.
Grid
I’m not really sure whether it’s part of the algorithm or not, but it’s worth mentioning that constraint based solvers work on a wide variety setups. While I’ve mostly been illustrating a square grid and tiles, there’s actually a lot of flexibility. The tiles can be images, game objects, or individual pixels.
And there’s many grids to choose from. You can have regular grids, such as square, hex or triangle grids, or you can have irregular ones, such as a sphere, or whatever you’d call the messy grids of Townscaper.
Summary
I think that covers most of the main variants I’ve seen. I’d definitely check out the following products, which showcase taking WFC and Model Synthesis beyond the standard implementation:
Beyond the algorithmic side, it really takes a good eye to take a generator and tweak it into something that gives the results you want. No one wants repetitive uninteresting outputs. Hopefully this article has give you some ideas to explore about how to avoid it.